You Can't Out-Model a Broken System
Everything being described was a model, and nothing being described was an outcome. The model works. The system around it doesn't.
AIM / RAISE Framework
What the AIM Index is actually measuring impact — and why most AI investments fail the readiness test, execution.
The market is still judging AI by the model. The real question is whether the organization is ready to turn that model into an operating outcome.
The Boardroom Pattern
A few weeks ago I was in a boardroom listening to their AI strategy. The slides were elegant. The budget was committed. The vendor list was current. And yet halfway through the discussion I felt the familiar quiet failure mode of this category: everything being described was a model, and nothing being described was an outcome.
This is the pattern underneath most underperforming AI initiatives. The model works. The system around it doesn't. And the gap between those two facts is where hundreds of millions of dollars a year quietly evaporate across the industrial and enterprise economy.
So we built something to make that gap visible.
Why We Published a Public Leaderboard
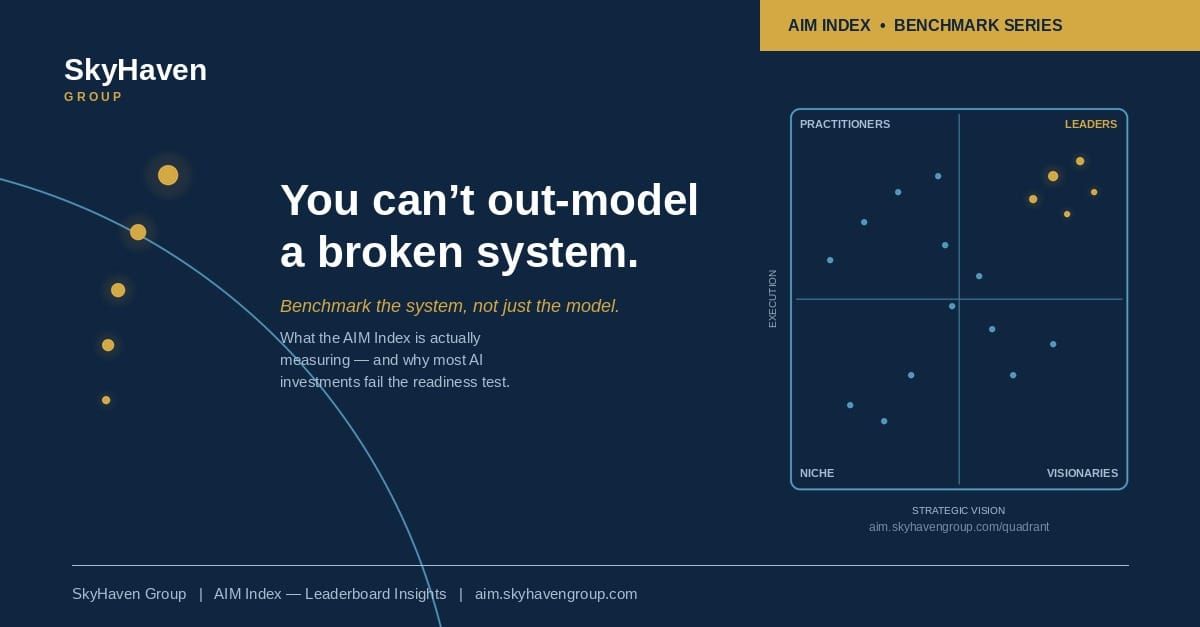
The AIM Index Leaderboard is live. It covers 147 companies across 23 sectors. Microsoft is the inaugural leader (this is evergreen) with a score of 82 out of 100. There is clear middle and bottom. There is a quadrant view that plots execution against strategic vision and sorts every covered organization into Leaders, Practitioners, Visionaries, or Niche.
The reaction from the market has been informative. A lot of executives look at the leaderboard and ask the right question:are we making the right investment? A smaller number look at it and ask the better question: what does the score actually mean, and what would I have to do to change it?
This article is for the second group.
The Thing We're Actually Measuring
The score is produced by RAISE — Readiness Assessment for Intelligent Systems Excellence. It is a six-dimension diagnostic, each dimension weighted by its demonstrated impact on time-to-value. It is not a model benchmark. It is a systems assessment. That distinction is the point.
The six dimensions are strategic alignment and leadership vision, data infrastructure and accessibility, use case maturity, AI governance and risk readiness, technical deployment capabilities, and change management and talent readiness. With multiple inputs into each of those six categories that are scored. Then weighted and the sum produces a number out of 100. That number is the assessment and the ranking.
Strategic alignment and leadership vision
The direction, sponsorship, and executive clarity needed to make AI more than a tool experiment.
Data infrastructure and accessibility
The operating foundation that determines whether systems can reach usable, trusted data.
Use case maturity
The quality of the value thesis, workflow fit, and operational path to measurable impact.
AI governance and risk readiness
The control structure required to deploy safely, repeatedly, and with accountability.
Technical deployment capabilities
The engineering capacity to move from prototype to production and keep systems running.
Change management and talent readiness
The adoption muscle that turns model output into changed behavior.
The weighting is where most readiness frameworks get soft. Ours does not. Strategy, data, and use cases are weighted most heavily because our evidence says they are the binding constraints on whether anything you build actually ships into production and produces an outcome. A firm with immaculate governance and weak data will not ship. A firm with strong data and no strategy will ship the wrong things and claim the roadmap was always going to evolve.
The Three Failure Modes
When we run a RAISE assessment, the output is a score. But the more useful output is the shape of the score — which dimensions are strong and which are weak. In practice, underperforming AI programs almost always cluster into one of three patterns.
Vision without execution
These are the organizations on the quadrant we label Visionaries. The narrative is strong. The ambition is real. A Chief AI Officer may be in place. But the data estate is fragmented, the governance is aspirational rather than enforced, and the workforce has no idea how any of this changes their Tuesday. The deck is excellent. The ship date is always next quarter.
Execution without vision
The Practitioners. Usually well-run industrial or operationally disciplined firms with mature IT and engineering functions. Competent models get shipped into the business. None of them compound, because there is no thesis about where AI changes the slope of the operating model. Point solutions accumulate. The AI budget grows. The impact doesn't.
Neither
The Niche quadrant. Low execution, low vision. These organizations have usually outsourced the AI question to a single vendor relationship or deferred the conversation entirely. The risk is not that they lose an AI race. The risk is that their cost structure and decision velocity fall out of line with competitors who have compounded even modest capability over two or three years.
If you can place your own organization in one of those three patterns within sixty seconds, you already know something important about where the next investment dollar should go.
The Three-to-Five Problem
Here is the data point that does the most to explain why AI investments underperform.
For every dollar an enterprise spends on the technical build of an AI solution, the evidence from companies like McKinsey (anecdotal), suggest another three to five dollars should be spent on change management, adoption, and the organizational work that actually turns a model into a behavior.
Most enterprises spend the one and skip the rest. Then they run a steering committee review six months later and discover that the model works perfectly and almost no one is using it.
The story we share in our workshops is instructive that you don't stop after building, adoption is part of the process. The story we share is an amalgamation of activities where the tools didn't need to change, but the system around it did; the discovery, the peer demonstration, the permission to use it for something, etc.
This is what we mean when we say evaluate the system, not just the model.
Reading Your Position Like a Strategist
A score on its own is a vanity metric. A score with a sequence behind it is a plan. Here is the three-step reading we give every client that comes through a RAISE engagement.
Identify the binding constraint
Your lowest-scoring dimension is almost always where the next dollar should go. Not because it is the most exciting area, but because it is the one holding everything else back. The most common mistake we see is an organization investing another round in use-case exploration when the real constraint is data access. The new use cases will not ship either.
Identify the compounding dimension
Your highest-scoring dimension is the one to lean into. Compounding matters more than balancing a radar chart. An organization that is truly strong in one or two dimensions and invests into that strength will outproduce an organization that tries to be average on all six.
Pick a lighthouse project
Modest in scope, high in visibility, squarely inside the dimensions where you already have readiness. Ship it. Let it become the proof point the rest of the organization rallies around. Capability compounds from shipped wins, not from steering committees.
What the Leaderboard Is For
Public leadersboards exist for a specific reason. They force conversations that the covered parties would otherwise prefer not to have. That is what U.S. News & World Report rankings do for universities. It is what the J.D. Power rankings do for auto manufacturers. It is, increasingly, what the AIM Leaderboard is doing for major enterprises, are we ready to use AI successfully?
Some of the ranking will raise eyebrows but we hope its more than that, informative. The discomfort it will create is productive. An assessment that is lower than expected is the single most valuable piece of signal a transformation team can receive, because the gap between perceived and actual readiness is where almost all wasted AI spend lives.
A readiness score that is higher than expected is also useful, but for a different reason. It raises the next question, which is whether the score is keeping pace with what competitors are building. Leadership is a position, not a destination.
What Happens Next
Over the next three weeks we are publishing a white paper series that goes deeper on the three questions we hear most from readers of the leaderboard.
The Readiness Gap
What actually separates a Leader from an On Pace organization in the same sector — and how the difference compounds over multiple investment cycles.
The Compounding Dimension
Why equal investment across all six RAISE dimensions is usually the wrong strategy, and how to identify the dimension where your next dollar will do the most work.
Change Management as the Binding Constraint
The three-to-five problem head-on — why the organizational work around the model determines whether any of it produces a result.
If any of this lands, I would encourage three things. Pull up the leaderboard and find your company or your closest peer. Name the one dimension you would rank lowest if you scored yourself honestly. Identify the one project in flight that will not ship until that constraint is resolved. Then decide what to do about it.
The leaderboard is at aim.skyhavengroup.com. The rest is a conversation.